Shared Memory Atomic throughput on RTX 4090
There are two categories of shared memory atomic operation: those 😊with😊 hardware support and those 🙁without🙁. The following operations have direct hardware support: 32-bit integer add, 32-bit integer max, and 32-bit bitwise operations. All other operations are implemented with Compare-And-Swap loops that are much slower under contention.
Here are some explanations of atomics and shared memory so that you can understand the context.
introduction to Atomic
Many operations that we think of logically as a single operation are composed of multiple smaller operations. Let's say you have a web server serving requests with many threads and you want to count how many requests you receive. You do this by incrementing a value in memory by 1 for every request: in C(*request_counter)++. We think of "incrementing a value in memory by 1" as being a single logical operation but in fact it is composed of three operations:
- Load value from memory into registers
- Increment value in register by one
- Write value from register to memory
These operations are not connected in the processor and happen separately.
Now imagine you have two threads that receive a request at exactly the same time and try to update the counter:
Thread 1 | Thread 2
Read value(0) | Read value (0)
Increment (1) | Increment (1)
Write back (1) | Write back (1)
The counter now records you have received one request when you actually received two.
To fix this, we make the single logical operation a single physical operation ("atomic", in the sense of "indivisible"). It now becomes a single instruction that the hardware guarantees will always be indivisible.
Compare-And-Swap
Often we would like to implement atomic operations that the hardware does not support natively, for example appending a value to a list. To do this we want a lock, and to implement a lock we use compare-and-swap (CAS). The idea being CAS is that we attempt to replace a value in memory with another value (swap) *only if* the current value is equal to a value we provide (compare) and return the prev. To implement a lock I might have a value in memory where 0 means the lock is not taken and 1 means it is. To try to take the lock, we would do the following:
while (compare_and_swap(memory_location=lock_ptr, compare=0, replace_with=1) == 1) {} // take lock
// write value to end of array
*lock_ptr = 0; // release lock
This will try to set the lock value to 1 over and over until it succeeds. This is also known as a spinlock.
We can implement any operation we want on top of this, for example we can implement our own increment instead of using a hardware increment instruction:
int old = *request_counter; // load the value initially
int assumed;
while (assumed != old) {
assumed = old;
int incremented = assumed + 1;
// get the value it was before the compare-and-swap attempt. If it was the value we thought it was, exit out. Otherwise, try to compare-and-swap again with the incremented new value.
old = compare_and_swap(memory_location=request_counter, compare=old, replace_with=incremented);
}
Because CAS is so flexible, we can implement anything we want as the operation -- atomic multiplication, atomic log-sum-exp, atomic XOR-then-shiftleft etc.
introduction to Shared Memory
In general, the more localized and limited communication is, the more efficient it is to implement in hardware. Therefore NVIDIA hardware is optimized to provide several levels of communication of different flexibility so your programs can use the least expensive communication possible.
In CUDA, programs execute in units of what NVIDIA calls a "warp"4 which is analogous to a CPU thread. Each warp has 32 "threads", analogous to SIMD lanes. GPUs have many registers, 256KB per SMs, which allows them to implement an aggressive form of hyperthreading where up to 64 warps can be running at the same time. This makes masking the latency of expensive memory accesses easy, because while one warp is waiting for data other threads can be computing. Communication between threads in a warp can be done using warp shuffle functions.
The next highest level of hierarchy is that multiple warps can be grouped into a "CTA" or "block" which are all guaranteed to run on the same SM, which consists of 4 SMSPs plus 128KB of "shared memory" which is like very fast addressible L1 cache. Multiple warps can communicate and work together through shared memory. For example in a matrix multiplication kernel many warps do different computations on the same data, reducing memory bandwidth.
In order for the warps in a block to communicate together they often need atomics: to track the maximum value they've seen, to calculate a sum, to keep a list or queue.
Here is the list of shared memory atomic SASS instructions.5.
ATOMS.ADDAtomically add a u32/i32 cudaATOMS.POPC.INC Increments a u32/i32. It's very fast (<10 cycles) and never suffers from contention. Discussed here cuda ATOMS.{MIN,MAX} Atomically min/max a u32/i32 cudaATOMS.{XOR,OR,AND}Atomically apply 32 bit wide bitwise operations cudaATOMS.CAS.{32,64,128}Atomically Compare-And-Swap a 32/64/128 bit value. These can be generated with user code. cudaATOMS.CAST.SPIN.{32, 64}Atomically Compare-And-Swap a 32/64 bit value. These are only generated by ptxas in loops (where you SPIN) to implement atomics not supported natively.
Here's an annotated example of what that inner loop looks like for an atomic not supported natively, like atomicAdd((float *)ptr, 15).
.LOOPSTART:
LDS R2, [R0] // Load current value from shared memory and put it in R2
FADD R3, R2, 15 // Add 15 to R2 and put it in R3
ATOMS.CAST.SPIN R3, [R0], R2, R3 // Attempt to replace the value at *ptr with R3 if *ptr==R2
ISETP.EQ.U32.AND P06, PT, R3, 0x1, PT // If the CAS failed
@!P0 BRA `(.LOOPSTART) // Loop back
This has several implications:
- If many threads are trying to update the same value, they do so sequentially (trying to get at: many issue an atomic CAS, only one succeeds)
- Non-int32 atomics are ~100x slower under extreme contention 6
- Updates that don't change the initial value (e.g. INF + 5 = INF) are meaningfully faster
- Manually implementing atomics in CUDA is just as fast as using builtins like atomicAdd() (for non-int32 operations)
- Operations not supported in CUDA like "atomic multiply" or "atomic exponent" are just as fast as atomicAdd() (for non-int32 operations)
- Any operations that can be converted from CAS operations into hardware operations should be.
Here are some graphs to substantiate these claims.
This is unfortunately incomplete. The original code for all of these is here, in blog.ipynb.
First, the headline numbers. This shows the number of cycles per atomicAdd() from each of 256 threads to a varying number of values. The X axis is the average number of threads trying to write to a particular address and the Y axis is the number of cycles. Both are on a log scale.
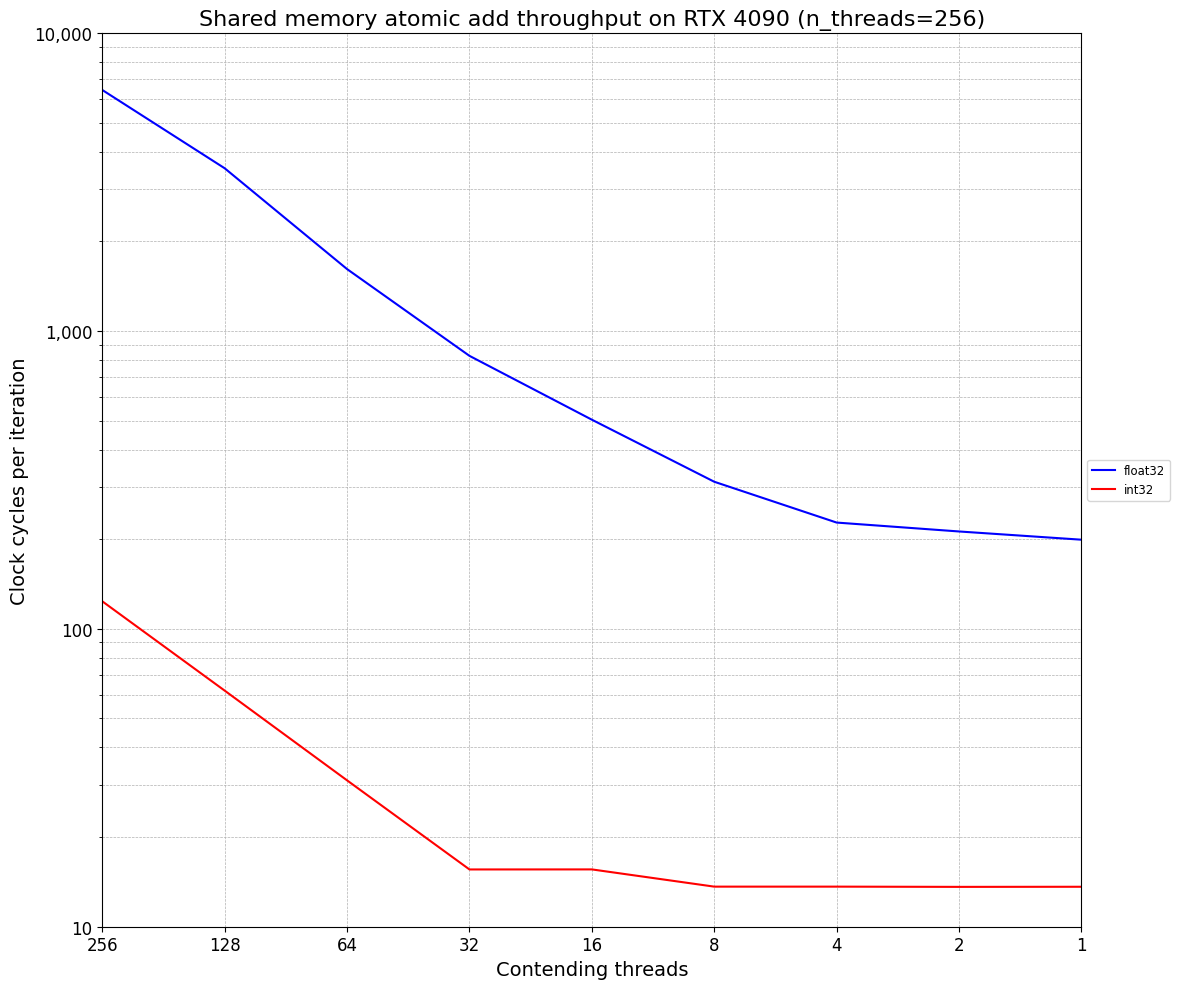
We can see that under heavy contention, float32 atomicAdd()s are about 50x slower than int32 atomicAdd()s. Even under no contention at contending threads=1, int32 atomicAdd()s are about 10x faster than float32 atomicAdd()s.
A note on a common pattern: Lines stay closely log-linear (2x reduction in contention means a ~2x reduction in runtime.) until a kink at which time stops reducing almost at all (here for int32 at 32 and float32 at 4). Often this kink comes because of bank conflicts.
Some operations that by default are expensive CAS operations can be converted into a single hardware operation or a series of hardware operations. Notably: float32 max can be implemented with int max, 64 bit AND/OR/XOR can be implemented with two 32 bit operations, int64 add can be implemented with two in32 adds. The easiest and most useful of these is float32 max. Graphed below is float32 max with CAS vs float32 max with int max.
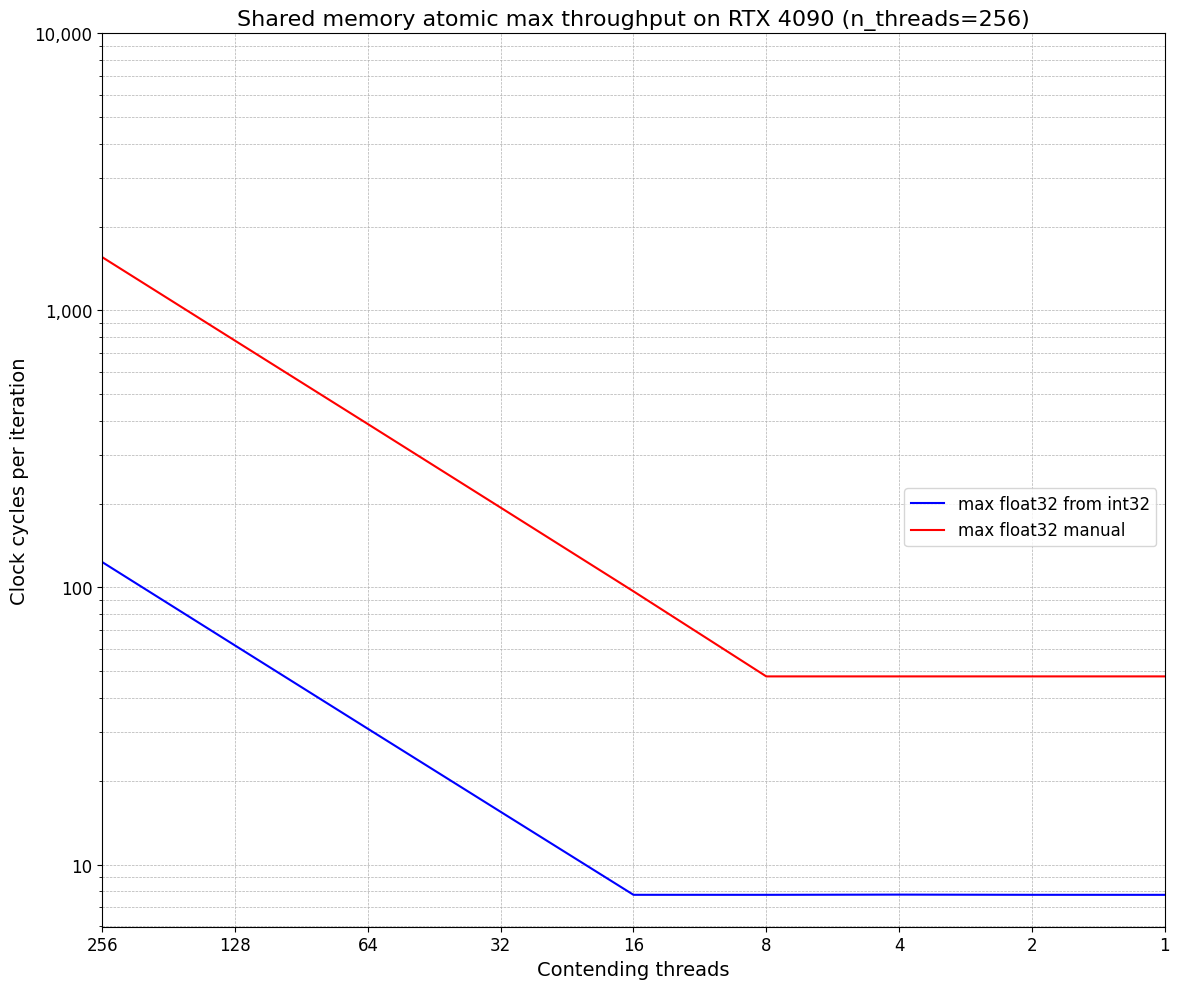
We can see int32 max is about 10x faster and has better contention behavior. Implementations of 64 bit add/AND/OR/XOR -> 32 bit are left to the reader :p
This is an expanded version of the first graph, with two new lines: "add manual", which uses a CAS loop in CUDA, and "add nochange", which sets the initial value being atomicAdd()ed to to be +INF, so atomics never change the value.
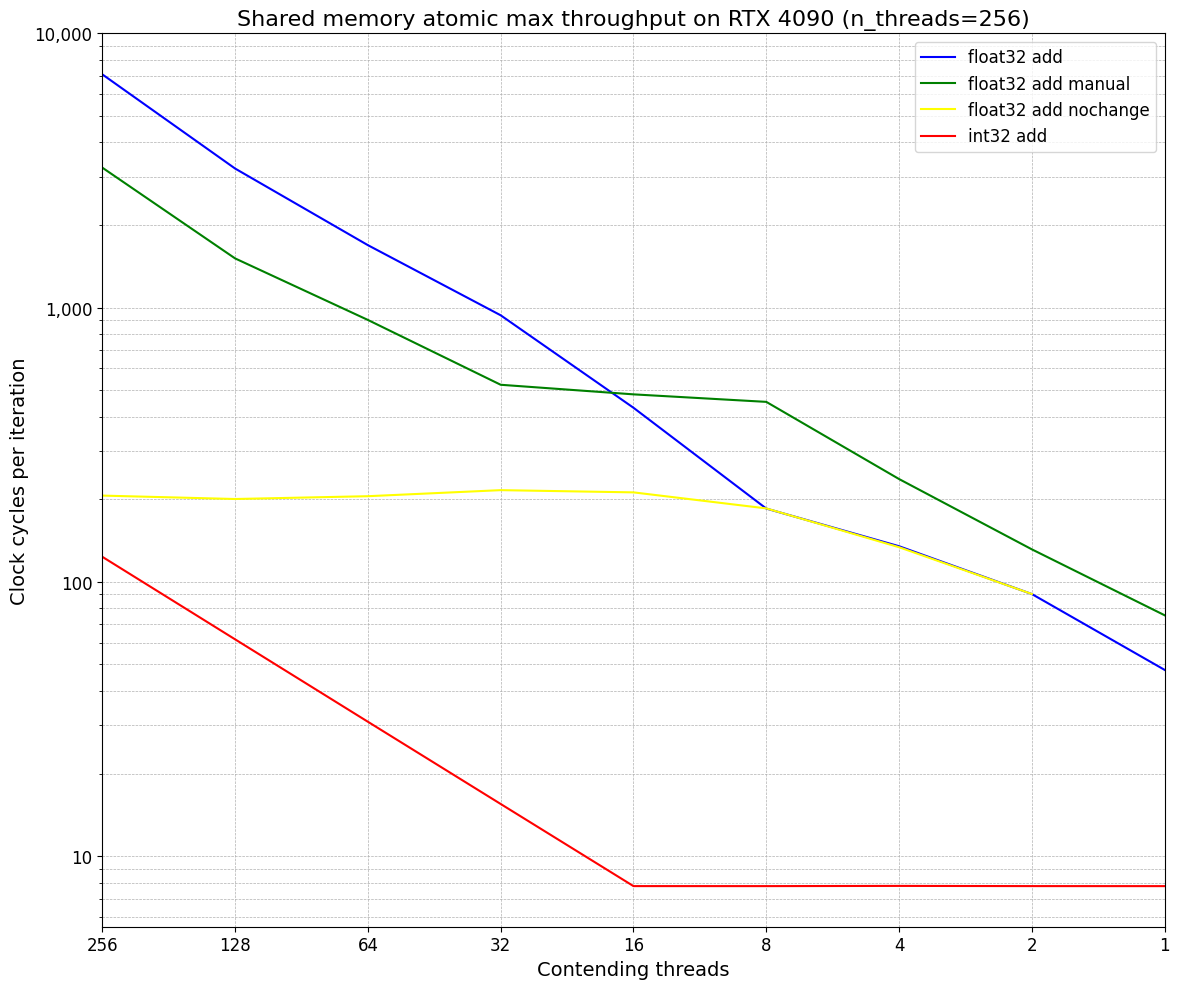
As we suspected, "nochange" improves performance significantly under high contention. This is because we are performing a CAS with the same value before and after.
Manual is almost the same speed but confusingly sometimes faster than atomicAdd(). My only guess at why this is is that atomicAdd() is not optimized for high contention (reasonable).
There are two compare-and-swap instructions: one that can be used from CUDA directly6, ATOMS.CAS (32/64/128), and one that
References
: There are good reasons why spinlocks are bad on the CPU (cf Linus) that don't apply on the GPU because there's no scheduler.
: because it was the first "parallel thread technology"
: I'm ignoring ATOMS.ARRIVE (AKA mbarrier.arrive.shared) because it doesn't seem important. Otherwise, we can be pretty confident about this because of Kuter Dinel's good work -- he listed all the modifiers for ATOMS, the generic instruction for "Atomic Operation on Shared Memory".
: "Predicate register 0". Predicate registers are special registers that hold a boolean for every lane in a warp, which then enables you to only execute an instruction for lanes where the predicate is true/false. The ISETP sets P0 to a value indicating whether the CAS succeeded, then @!P0 BRA `(.LOOPSTART) makes all the lanes where the CAS failed start over.
: Specifically with atomicCAS(), which is atom.shared.cas in PTX
: (NOTE: mention __shfl_sync, mention random index stuff too)